Ordered Action Tokenization
OAT turns continuous robot actions into compact tokens whose trained prefixes progress from coarse motion to finer detail.
1Harvard University · 2Stanford University
What is an action token?
A robot action chunk is a short future sequence of continuous commands: how the joints should move, how the gripper should change, and so on. An action tokenizer compresses that whole chunk into discrete symbols; a detokenizer maps the symbols back to continuous motion.
In a vision-language-action (VLA) policy, a vision-language model (VLM) connects camera observations and language instructions to robot control. Action tokens can play two roles: the VLM can generate and decode them, or learn from them while a continuous action expert produces the motion. Either way, tokenization determines the policy's targets, their length, and the structure the model learns from.
OAT's central idea is simple: train even a short prefix to reconstruct the whole action chunk, then train larger prefix budgets to refine it. The method, Prefix Lab, and experiments below show how this ordering is learned and measured.
Five terms used throughout this page.
- Action chunk
- A short future sequence of continuous robot actions, written as \(a_{1:H_a}\in\mathbb{R}^{H_a\times D_a}\).
- Action token
- A discrete symbol \(T_i\in\mathcal{V}\) used as an AR prediction target or as token supervision for a VLM.
- Ordered prefix
- A prefix \(T_{1:k}\) that can already decode to a complete coarse action chunk.
- BAR
- A block-wise autoregressive generation method that grows an action-token prefix in scheduled blocks.
- TC
- Token co-training: action tokens supervise the VLM, while a continuous expert controls the robot. Related work sometimes calls this knowledge insulation (KI).
What should action tokens guarantee?
In the usual rate-distortion view, token count is a proxy for rate and expected reconstruction error is distortion. Exact code length also depends on vocabulary size. But a low-rate, low-distortion code is not yet a good policy interface. It needs three guarantees.
An action chunk contains a command for every timestep and control dimension. Writing each value separately creates a long sequence. Compact tokens preserve control-relevant motion with fewer symbols, reducing the number of training targets and, when tokens are generated one at a time, VLA calls.
A policy can sample any sequence in its output space, not only codes produced by the tokenizer's encoder. Every fixed-length sequence of vocabulary indices that the policy can emit should map to a defined continuous action chunk without rejection, padding, truncation, or constrained generation.
Low full-sequence reconstruction error says nothing about where information lives. A useful order lets early trained prefixes reconstruct coarse, high-impact motion, while later tokens refine what remains. That structure can help both generation and VLM supervision.
Can several new tokens be predicted together?
Block compatibility is a separate condition for reducing VLA calls. If several new tokens are predicted together, tokens in that block cannot rely on seeing one another first, and both the tokenizer and policy must be trained for that grouping.
Where existing tokenizers fall short.
The first three columns evaluate the tokenizer itself. Block compatibility applies when one VLA call predicts several new tokens. Each existing format solves a different part of the interface.
How it works, and the cost Each coordinate at each timestep becomes a separate token. Every sequence decodes, but the target grows with the action and its coordinate order does not expose coarse trajectory structure.
OAT builds the order through prefix training.
OAT compresses an action chunk into registers and discretizes them with FSQ. Instead of training only the final token sequence, it repeatedly asks shorter prefixes to reconstruct the entire action.
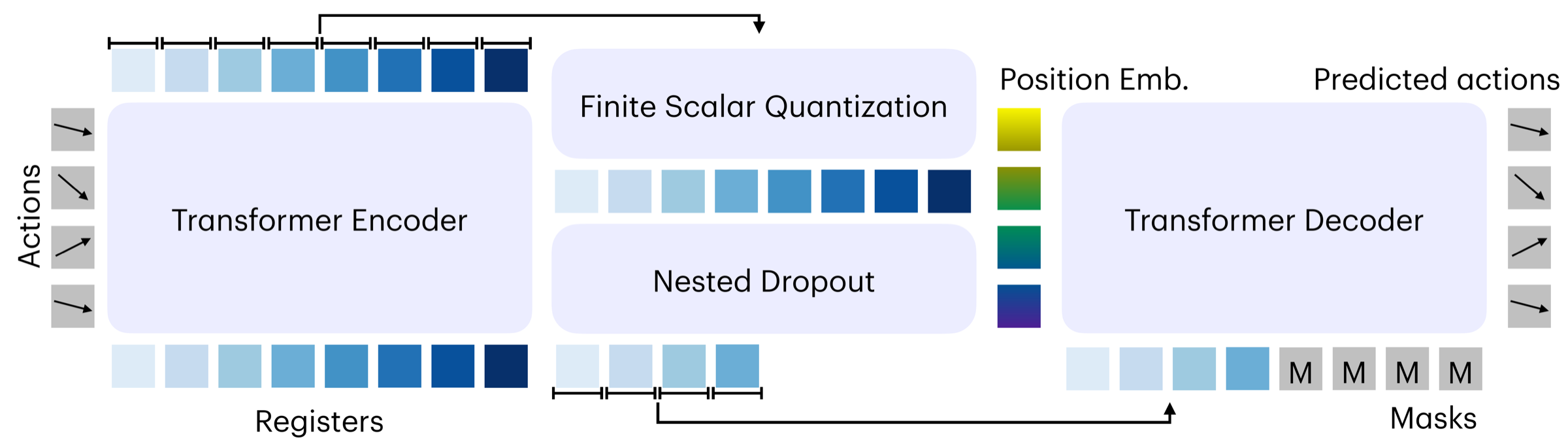
Transformer registers cross-attend to the complete action chunk, so each token position can summarize motion across time and control dimensions.
FSQ maps every register to a token from a fixed vocabulary. The learned decoder maps every fixed-length sequence from that vocabulary to a continuous action chunk, not only codes seen during encoding.
Training samples a budget, keeps that prefix, masks the suffix, and reconstructs the complete action. Each trained budget is a reconstruction point, not a fragment of coordinates.
Why useful information moves left.
Token 1 is present in every nonempty training prefix. Token 8 appears only when the sampled budget reaches eight or more. Early positions therefore help reconstruct the action under more budgets, so they receive more pressure to carry information that is broadly useful.
This asymmetric training pressure favors coarse, broadly useful information early and residual refinements later. OAT learns the order from variable information budgets; it does not assign tokens to coordinates, timesteps, or frequencies by hand.
Information-allocation derivation
Let \(\varepsilon(K)\) be the expected reconstruction error with the first \(K\) tokens, and let \(\Delta_i=\varepsilon(i-1)-\varepsilon(i)\) be the average improvement contributed by token \(i\). Sampling a prefix budget \(B\) gives
Token \(i\) is weighted by its survival probability \(\Pr(B\ge i)\), which cannot increase as \(i\) moves right. Earlier marginal gains therefore improve more sampled reconstruction budgets.
Causal register attention extends the sequence one token at a time, matching policies that predict one new OAT token per call.
Budgets grow as 1, 2, 4, 8, and so on. Ordering is learned across these groups; tokens introduced within one group have no imposed priority over one another.
Try the Prefix Lab to see the action sharpen as tokens are added. The MeshCat trajectories show the same idea on measured robot motions.
For VLM-scale AR, BAR makes the generation cost explicit.
OAT makes ordered prefixes executable, but a length-\(K\) prefix still costs \(K\) sequential VLA calls. BAR targets that serial depth by introducing a schedule over prefix boundaries, unifying token-wise AR, block-wise AR, and parallel decoding.

Choose how aggressively AR is blockified.
For a 16-token action-token sequence, the schedule determines sequential VLA calls and the largest joint prediction block.
The bar shows the realized prefix and the current block produced by this stage.
One new token per stage.
Maximum conditioning, maximum serial depth.
Every token gets all earlier tokens as context, but inference remains fully serial.
It decides how many tokens are generated per VLA call, trading serial depth against prediction difficulty.
The BAR policy learns joint block targets with block-shifted teacher forcing; the tokenizer must separately expose matching reconstruction budgets and dependencies.
Grouped generation must be matched across OAT and BAR training.
The BAR policy jointly predicts each scheduled block with block-shifted teacher forcing. The tokenizer solves a different, matching problem: power-of-two OAT trains reconstruction at the same endpoints and blocks direct dependencies among registers introduced within one group. Encoder, FSQ bottleneck, prefix decoder, and nested-dropout objective otherwise remain unchanged.
OATsing and OATpow2 train different dependency patterns.
BAR groups later action-token positions into one prediction step. The key question is whether the new block can be jointly predicted from the realized prefix without relying on serial dependencies inside that same block.
Flat causal chain
Rows are query registers; columns are key registers.
Later registers can depend on all earlier registers. This matches token-wise AR, but post-hoc BAR can group tokens whose tokenizer representations were learned with serial within-block dependencies.
Block-causal registers
Power-of-two blocks: [1] [2] [3-4] [5-8].
Registers attend across earlier groups and to themselves, but not to other registers in the same group. The tokenizer therefore avoids direct within-group serial dependencies; the BAR policy separately learns to predict that block jointly.
Schedule changes alone do not make OAT block-compatible.
With PaliGemma2 on LIBERO (mean success, 50 rollouts per task), post-hoc BAR reduces calls but loses success. Power-of-two OAT uses matched tokenizer endpoints and register dependencies, keeps the five-call schedule, and closes the gap.
It changes the decoding schedule, but the tokenizer was still trained with serial dependencies inside each scheduled block.
Its tokenizer budgets and register mask align with the blocks that the BAR policy is trained to predict jointly.
First verify the representation: every trained prefix must remain executable.
Before training a VLA policy, we measure whether each retained prefix actually adds action information. A short prefix should already decode to a coarse action; later tokens should buy refinement rather than repeat information the prefix already carried.
Nested dropout trains reconstruction across selected budgets, not only at \(\varepsilon(H_l)\). Token-wise OAT uses every token length; the separately trained power-of-two variant uses boundaries \(1,2,4,8,\ldots\). Both form progressive rate–distortion curves at their respective trained budgets.
Every trained budget decodes a complete action.
Each trained prefix decodes into the whole action, not a fragment. The sketch shows how the path becomes more precise as you add tokens; measured robot trajectories appear in MeshCat below.
One token decodes a complete action chunk, but the reconstruction is coarse and visibly offset from the ground truth.
Conceptual schematic, not a measured rollout. Green points show a reference path; red points illustrate the full chunk at a selected trained budget. The MeshCat panel below provides measured reconstructions.
Measured prefix reconstructions.
These MeshCat trajectories show decoder outputs at trained budgets of 1, 2, 4, and 8 tokens alongside the ground-truth action chunk.
A curve, not just an endpoint.
These curves evaluate the rate-distortion tradeoff across prefix budgets. A better representation reaches low expected reconstruction error with fewer tokens. An autoencoder trained only on full sequences optimizes one endpoint; OAT trains reconstruction at multiple prefix budgets.
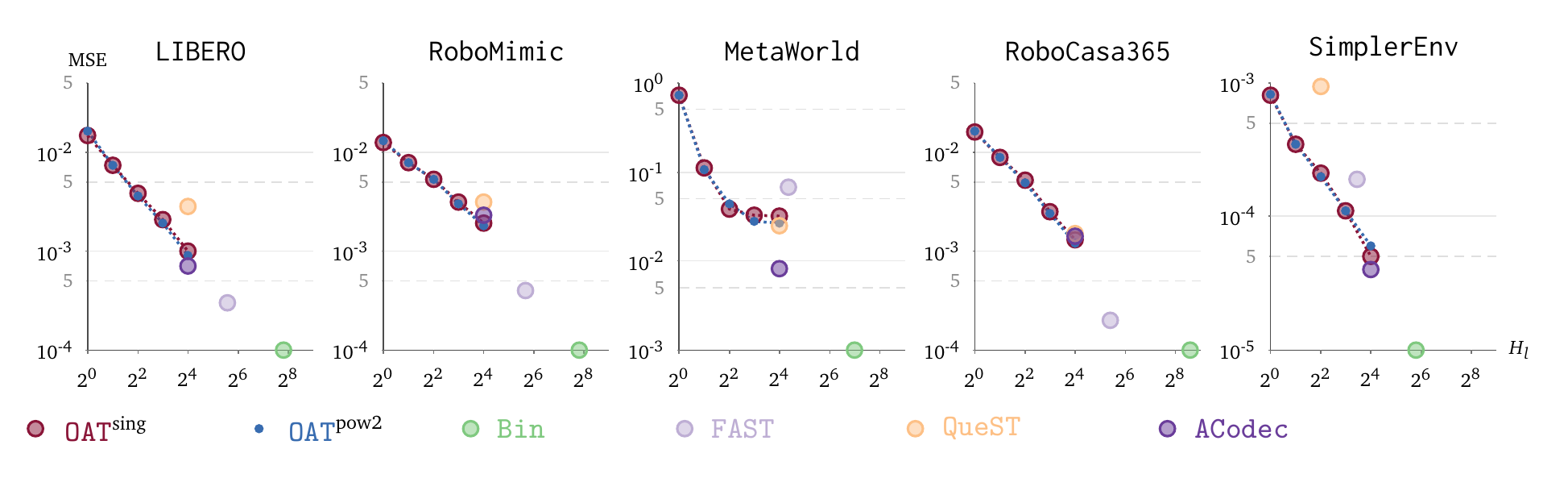
At each configured horizon, OAT represents the action chunk with far fewer tokens than coordinate-by-coordinate serialization.
Both versions reduce reconstruction error as more tokens are kept.
Each trained prefix decodes into a complete action chunk, not a fragment of coordinates or coefficients.
OAT explicitly trains intermediate reconstruction budgets. The fixed-length baselines shown here are trained and evaluated at their full sequence lengths. These curves establish progressive reconstruction; the VLA experiments below evaluate OAT as a whole rather than isolating ordering alone.
Generate OAT. Execute the action.
This is the strictest policy role: the VLM predicts the OAT sequence that is decoded into robot motion. Any failure in the generated token sequence now enters the control path directly.
Generate OAT in blocks.
This is where block compatibility matters. To predict several new tokens in one VLA call, every token in that block must be predictable from the observation and the realized prefix, without seeing the other new tokens first.
Block-wise autoregression chooses the block sizes. One VLA call means one sequential model prediction step for the current action chunk. One token per call provides the most serial conditioning; larger blocks reduce calls but create a harder joint prediction target.
For a 16-token action, the power-of-two schedule grows the prefix through 1, 2, 4, 8, and 16 tokens. Power-of-two OAT trains at those same boundaries and blocks direct register attention between tokens in the same new group. The VLM policy is separately trained to predict each block jointly from the context it will have during generation; a compatible tokenizer alone is not enough.
We test PaliGemma2 and Qwen3VL as VLM policy backbones. Success rate is the fraction of closed-loop evaluation rollouts that complete the task; the summaries below balance results across four benchmark suites, and higher is better.
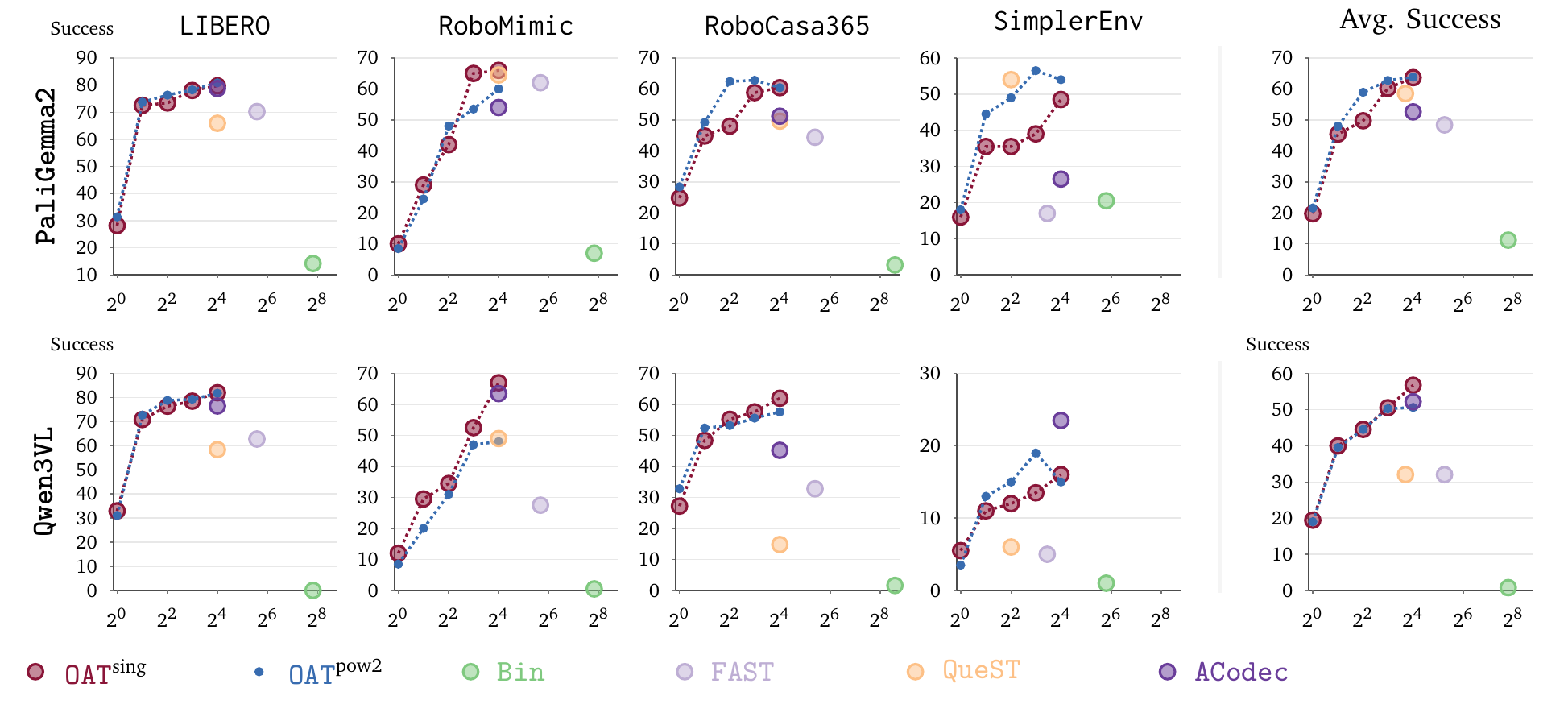
Two different VLM backbones can generate the ordered tokens well enough for closed-loop control. Grouping tokens can reduce model calls, but larger groups are harder to predict, and the best balance depends on the backbone.
OAT teaches the VLM. The expert acts.
Why train action tokens if the robot never decodes them? In token co-training, OAT provides structured action supervision to the VLM before it passes context to a continuous action expert. The tokens teach during training; the expert controls the robot at deployment.
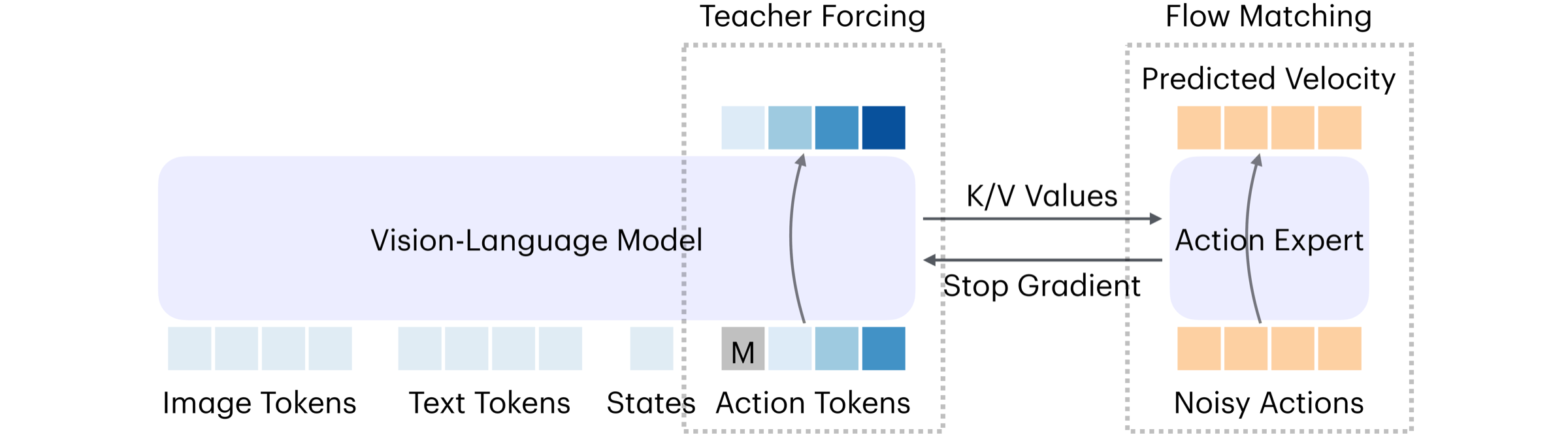
The OAT prediction loss updates the VLM. In parallel, the flow-matching loss trains the continuous expert from stopped-gradient VLM context, so the expert's loss does not rewrite the VLM.
For each policy query, the VLM encodes the image, language, and robot state. The continuous expert uses that cached context to produce the action chunk; no OAT sequence is generated or detokenized.
Change the tokenizer. Change the policy.
This comparison keeps the continuous controller architecture fixed and changes the tokenizer that supplies VLM training targets. We report closed-loop task success across the same four benchmark suites; higher is better.
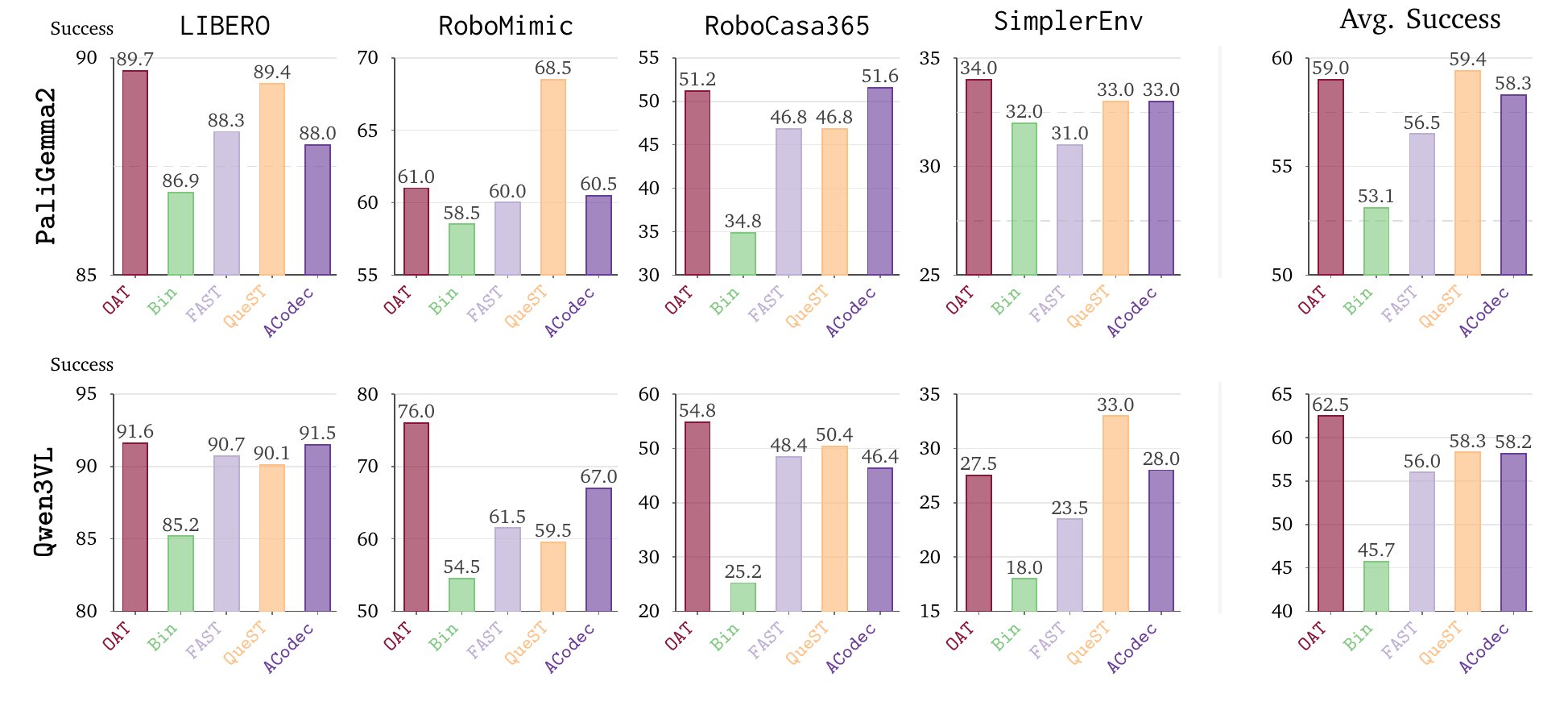
Tokenizer choice changes downstream closed-loop performance. OAT has the strongest Qwen3VL average and is numerically close to the strongest PaliGemma2 averages, though it is not best on every benchmark. This comparison changes the whole tokenizer, so it does not isolate ordering by itself.
Design tokens for the policy.
OAT represents an action with fewer symbols, maps every fixed-length vocabulary sequence to a defined continuous action chunk, and trains prefixes to organize information from coarse motion to residual detail. For grouped generation, its trained boundaries also match the prediction schedule.
Generated OAT is decoded directly into control and is evaluated across two VLM backbones and four benchmark suites.
If tokens will be generated in groups, train the tokenizer with those same group boundaries. Regrouping only at deployment is not equivalent.
Training-only tokens still shape the VLM context used by the continuous controller. Their structure is not disposable.
The visible VLA study covers two VLM backbones, four benchmark families, fixed controller designs, and token counts chosen before deployment. Adaptive stopping and broader robot coverage remain open questions.
Papers, code, and citations
Please cite the full paper for OAT in visuomotor policy learning, the RSS version for the original tokenizer, and Praxis when using the controlled VLA research platform.
Readers interested in controlled VLA experiments can use praxis-vla for training and praxis-eval for evaluation.
@misc{liu2026oatpolicy,
title={Ordered Action Tokens for Visuomotor Policy Learning},
author={Chaoqi Liu and Yue Zhao and Haonan Chen and Xiaoshen Han and Jiawei Gao and Ehsan Adeli and Yilun Du},
year={2026},
eprint={2607.21670},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2607.21670},
}@misc{liu2026oat,
title={OAT: Ordered Action Tokenization},
author={Chaoqi Liu and Xiaoshen Han and Jiawei Gao and Yue Zhao and Haonan Chen and Yilun Du},
year={2026},
eprint={2602.04215},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2602.04215},
}@misc{liu2026praxis,
title={Praxis: A Controlled Laboratory for Vision-Language-Action Policy Research},
author={Liu, Chaoqi},
year={2026},
url={https://chaoqi-liu.com/praxis/}
}