Ordered Action Tokenization
面向自回归机器人策略的有序动作 token:序列短、始终可解码,并让每个前缀都承载有效动作信息。
RSS 2026 录用论文,扩展自原始 文章, 并加入原生网页交互控件。
1Harvard University · 2Stanford University
动作 tokenizer 定义了策略要预测什么。
自回归机器人策略并不是直接预测连续控制信号。它先为一小段未来动作,也就是动作块,预测离散 token, 再依赖 detokenizer 把这些 token 还原成可执行的连续控制。因此,tokenizer 设计本身就是学习问题的一部分: 一种表示可以重建得很好,却仍然生成得慢、采样后不可解码,或者很难从左到右预测。
- 问题:现有 tokenizer 暴露出三重张力:压缩、全域可解码性,以及自回归可预测性很难同时满足。
- 方法:OAT 学习一组有序的离散 register token,并训练每个前缀都能解码成完整动作块。
- 结果:token 数变成运行时预算:简单动作可以用短前缀快速执行,复杂动作再生成更多 token 换取精度。
1. 动作 tokenizer 决定策略要预测什么。
离散动作 token 正在成为现代机器人学习系统中越来越重要的设计选择: RDT-2 在第一阶段训练中使用 vector-quantized (VQ) 动作 token; TRI 的 LBM/VLA 使用 FAST 和 VQ 风格的动作 token;而 BEHAVIOR 2025 Challenge 的 获胜方案 在训练和推理中集成了 FAST token。
在这些系统里,策略先看到符号,再看到控制。动作 tokenizer 决定序列有多长、采样出来的 token 是否能安全解码, 以及模型需要学习什么样的从左到右结构。它不是预处理细节,而是策略真正面对的预测问题。
2. 只看重建误差是不够的。
经典理论如 率失真权衡 关注压缩率和重建精度之间的平衡。对生成式机器人策略来说,还需要看第三个维度:可建模性, 也就是生成模型捕捉这种表示分布的难度。结构不好的表示可能既紧凑又准确,但从根本上很难建模。
核心区别就在这里:一个 tokenizer 可以很好地重建动作,却仍然不适合策略学习。如果 token 流很难被自回归模型预测, 或者稀疏且高熵,模型会在每一次下一个 token 预测中付出代价。
更短的动作编码可以降低自回归深度和延迟。
连续机器人控制仍然需要足够精度,尤其是接触丰富的执行场景。
token 顺序应该让下一个 token 预测更容易,而不只是让它可行。
对机器人控制而言,只有下游策略能可靠建模这些 token,tokenizer 才真正有用。 低重建误差当然重要,但它并不保证 token 序列具有稳定的从左到右结构。
3. 好的动作 tokenizer 必须紧凑、全域可解码,并且有序。
目标不是单个指标。面向自回归策略的动作 tokenizer,必须同时满足三项要求:
- (P.1) 合理压缩。 该表示应足够压缩动作块,以支持高效序列建模,但不能过度压缩到丢失太多信息。
- (P.2) 全域可解码。 detokenization 映射应当是定义良好的 全函数: 离散 token 空间中的每个 token 序列都必须解码成有效动作块。这一点很关键,因为策略在推理时可能生成任意 token 序列。 如果解码只在部分输入上有定义,无效 token 就可能导致未定义行为或执行中的灾难性失败。
- (P.3) 可预测排序。 token 序列应该具有有意义的从左到右因果结构,并与下一个 token 预测对齐。 这种结构对可建模性至关重要,使自回归模型能够学习稳定、可预测的 token 动态。
每类 tokenizer 放弃了什么?
选择一个 tokenizer 家族,把它放回三项要求里看:压缩、全域可解码,以及 自回归可建模性。
分箱方法全域可解码,但会产生又长又扁平的 token 序列,难以让自回归策略高效建模。
4. 在 OAT 之前,每类 tokenizer 都会放弃一项要求。
在 OAT 之前,主流 tokenizer 家族各自都会牺牲其中一项要求。 OAT 的目标正是同时满足这三点:紧凑、全域可解码,并且有序。
每个生成 token 都能解码,但策略必须生成数百个扁平的维度-时间 token。
频域结构有助于下一个 token 预测,但任意 BPE 序列可能无法解码。
神经解码器让输出可执行,但 token 序列的自回归可建模性较弱。
这些 token 被学习成渐进序列,因此早期预测携带粗粒度运动结构。
Binning. 最常见的方案是按维度、按时间步分箱。它很简单,但扩展性差:长时域和高维动作可能让每个动作块产生数百个 token, 显著拖慢训练和推理并增加延迟。更重要的是,这类又长又扁平的序列在跨维度上可建模性较差: 已经知道一个时间步里的前几个坐标,对预测下一个坐标帮助很小,因此不太适合自回归生成。
频域变换。 FAST 等基于频率的方法具有高信息密度 (P.1),并引入从低频到高频的结构 (P.3): 早期 token 捕捉全局轨迹结构,后期 token 细化细节。然而,FAST 违反了 P.2(全域可解码性)。因为 Byte Pair Encoding (BPE) 会产生可变长度序列,任意 token 序列未必能解码成有效的固定大小频域表示,从而导致未定义行为和运行时失败。 更多细节见论文附录以及 Hugging Face 上的讨论。
普通 latent 表示。 学习式 encoder-decoder latent tokenizer 可以获得较强压缩 (P.1),神经解码器也能保证全域可解码 (P.2)。 但所得 token 空间通常自回归可建模性较弱:token 位置没有为下一个 token 预测提供稳定的从左到右结构。 这使其难以适配依赖有意义左到右结构 (P.3) 来稳定生成的策略。
问题并不是先前 tokenizer 在所有方面都弱,而是没有一种方法同时做到:序列短、整个 token 空间都可执行, 并且给策略一个容易从左到右预测的问题。
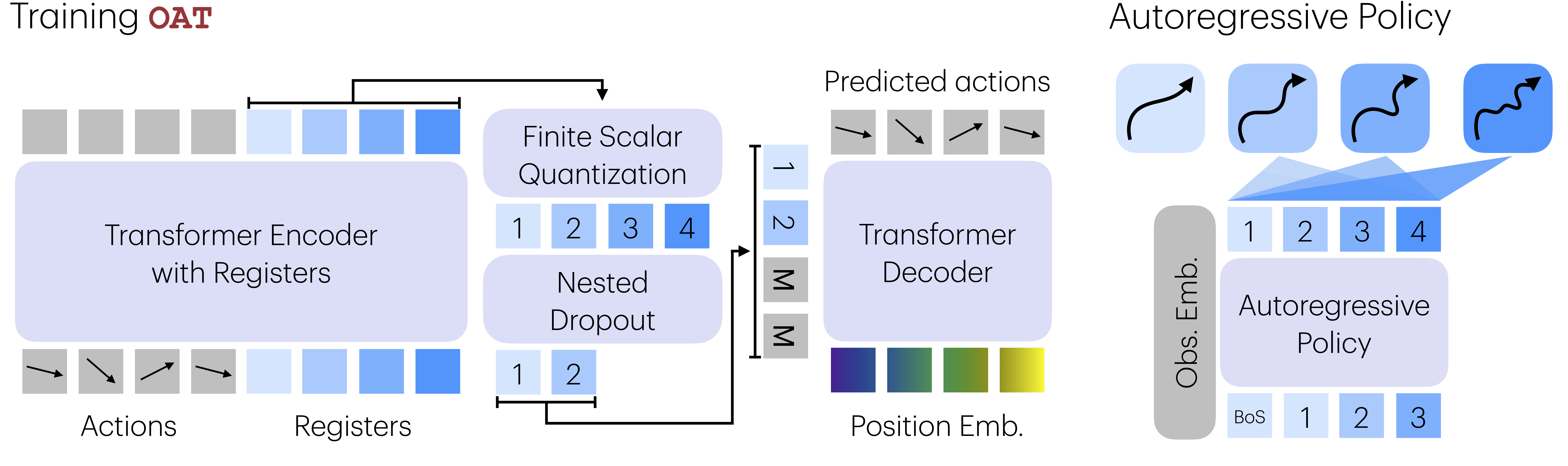
5. OAT 学习有序 register token,并让任意前缀都能解码。
OAT 是一个学习式动作 tokenizer。它把每个动作块写入固定数量的 register token, 用 finite scalar quantization (FSQ) 将这些 token 离散化,再把生成的 token 解码回连续控制。 关键设计是“顺序”:register token 之间的注意力是因果的,nested dropout 则训练解码器从部分前缀重建动作。
- 概括动作块。 Transformer encoder 读取连续动作序列,并把重要时间信息写入固定数量的 register token。
- 离散化 register token。 Finite scalar quantization 把 register token 转成自回归策略可以预测的离散 token。
- 强制从左到右结构。 因果注意力让后面的 register token 依赖前面的 register token,使表示与下一个 token 生成对齐。
- 用缺失尾部训练。 Nested dropout 在 tokenizer 训练中随机遮蔽后续 token,因此早期 token 必须承载最高优先级信息。
- 解码回控制信号。 条件解码器把生成的 token 前缀映射回可执行的连续动作块。
6. 有序 token 把动作编码变成渐进细化。
OAT 引入的排序可以从信息论得到自然解释。 Shannon 表明, 一个事件越常见,编码它所需的容量越少;越罕见,就需要更多表示容量。 动作块也有类似的偏斜分布:大多数轨迹共享常见的粗粒度结构,而细粒度偏差较少出现。
从这个角度看,OAT 学到了一种渐进编码。早期 token 捕捉高概率、全局共享的运动模式, 后期 token 编码越来越少见的残差细节。Nested dropout 把这种压力显式写进训练过程:每个短前缀都必须重建动作, 因此信息会按有用程度递减的顺序被分配。
第一个 token 不是任意 latent 位置;它被训练成携带最高优先级的控制信息。
额外 token 降低残差误差,而不是替换掉前缀已经表示的动作。
7. 每个前缀都是可执行的动作预算。
因为 OAT 在训练时让解码器见过被遮蔽的后缀,策略不必等完整 token 序列生成完才行动。 一个前缀可以先补齐,再交给 detokenizer 解码成完整动作块并执行。实践中,token 数就变成运行时预算: 一两个 token 用来快速产生粗粒度控制,需要精度时再生成更多 token。
提前停止,动作仍然有效。
OAT 让每个前缀都可执行。更多 token 会细化轨迹,但在延迟重要时,策略可以提前停止。
1 个 token 可以解码出完整动作块,但重建较粗糙,且与真实轨迹有明显偏移。
每个前缀都会解码成完整动作块。绿色点是真实路标;红色点是从所选前缀重建出的完整动作块。 更多前缀 token 会减少红绿误差,并提升细粒度保真度。
8. OAT 同时改善成功率、延迟和真实执行。
我们在 20 多个任务上评估 OAT,覆盖四个仿真基准 (LIBERO, RoboMimic, MetaWorld 和 RoboCasa) 以及真实机器人执行。实验要回答的是: 有序前缀是否只是好看的表示,还是确实能带来更强的闭环策略?
OAT8 在所有报告的成功率列中都是最好结果。
OAT1、OAT2 和 OAT4 降低了自回归深度,同时仍然能解码成有效动作。
去掉排序目标后,结果低于 OAT4 和 OAT8,说明因果注意力和 nested dropout 确实在帮助策略学习。
完整 OAT 在仿真和真实任务上都取得最好结果。
OAT8 在每个仿真基准和两个真实任务中都取得最好成功率, 同时保留了固定长度 tokenizer 不具备的前缀执行能力。
| 策略 | LIBERO | RoboMimic | MetaWorld | RoboCasa | PnP Ball | Stack Cups |
|---|---|---|---|---|---|---|
| DP | 36.6 | 67.1 | 19.3 | 54.0 | 14/20 | 11/20 |
| Bin | 14.4 | 39.5 | 14.5 | 27.7 | 4/20 | 8/20 |
| FAST | 23.0 | 24.0 | 7.1 | 13.2 | 8/20 | 6/20 |
| QueST | 48.2 | 66.9 | 17.9 | 52.3 | 11/20 | 8/20 |
| OAT1 | 11.7 | 50.8 | 11.3 | 47.7 | 7/20 | 3/20 |
| OAT2 | 39.8 | 52.5 | 16.4 | 50.3 | 11/20 | 9/20 |
| OAT4 | 46.4 | 65.3 | 19.5 | 51.7 | 13/20 | 12/20 |
| OAT8 | 56.3 | 73.1 | 24.4 | 54.6 | 16/20 | 16/20 |
完整 OAT 与 QueST 的八 token 延迟相当,但短前缀快得多。
完整解码时,OAT 和 QueST 的自回归深度相近。区别在于, 当延迟更重要时,OAT 可以停在 1、2 或 4 个 token。
| 策略 | LIBERO | RoboMimic | MetaWorld | RoboCasa | ||||
|---|---|---|---|---|---|---|---|---|
| #Tok. | 延迟 | #Tok. | 延迟 | #Tok. | 延迟 | #Tok. | 延迟 | |
| DP | × | 42.0 | × | 38.1 | × | 37.7 | × | 35.3 |
| Bin | 224 | 517.2 | 224 | 509.5 | 128 | 306.6 | 384 | 888.3 |
| FAST | 44.2 | 114.4 | 53.1 | 142.0 | 49.8 | 129.7 | 69.7 | 166.1 |
| QueST | 8 | 27.1 | 8 | 29.6 | 8 | 31.4 | 8 | 30.2 |
| OAT1 | 1 | 10.5 | 1 | 11.3 | 1 | 15.5 | 1 | 13.5 |
| OAT2 | 2 | 13.2 | 2 | 15.3 | 2 | 17.9 | 2 | 15.8 |
| OAT4 | 4 | 17.4 | 4 | 18.4 | 4 | 22.1 | 4 | 19.8 |
| OAT8 | 8 | 27.4 | 8 | 29.9 | 8 | 31.3 | 8 | 30.0 |
顺序不是装饰,它直接影响策略学习。
在四个仿真基准上,移除诱导排序的目标都会导致稳定下降。 OAT× 的性能显著弱于 OAT4 和 OAT8,部分情况下甚至低于 QueST。
| 策略 | LIBERO | RoboMimic | MetaWorld | RoboCasa |
|---|---|---|---|---|
| QueST | 48.2 | 66.9 | 17.9 | 52.3 |
| OAT1 | 11.7 | 50.8 | 11.3 | 47.7 |
| OAT2 | 39.8 | 52.5 | 16.4 | 50.3 |
| OAT4 | 46.4 | 65.3 | 19.5 | 51.7 |
| OAT8 | 56.3 | 73.1 | 24.4 | 54.6 |
| OAT× | 35.2 | 61.1 | 17.6 | 48.5 |
前缀越长,同一个动作就越清晰。
这些 MeshCat 重建展示了前缀预算背后的机制:早期 token 恢复粗粒度运动,后续 token 继续细化残差细节。 所有轨迹都由同一个 tokenizer 和 decoder 生成。
真实执行暴露出同样的失败模式。
90 多个真实机器人视频覆盖不同任务、tokenizer 和相机视角下的成功与失败尝试。重新加载会随机化初始配置。 FAST 的失败常常暴露出可解码性问题:当采样 token 无法安全解码时,策略只能停下,而不是执行一个未定义动作。
DP
该任务没有可用视频。
该任务没有可用视频。
Bin
该任务没有可用视频。
该任务没有可用视频。
FAST
该任务没有可用视频。
该任务没有可用视频。
QueST
该任务没有可用视频。
该任务没有可用视频。
OAT1
该任务没有可用视频。
该任务没有可用视频。
OAT2
该任务没有可用视频。
该任务没有可用视频。
OAT4
该任务没有可用视频。
该任务没有可用视频。
OAT8
该任务没有可用视频。
该任务没有可用视频。
9. token 顺序把表示设计变成控制决策。
OAT 的核心并不是用离散 token 取代连续控制器。 关键在于:一旦机器人策略开始使用动作 token,token 的顺序就会成为控制问题的一部分。 紧凑性、全域可解码和前缀可建模性需要一起设计;当这三点同时成立时,token 数量就不再只是预处理阶段固定下来的超参数, 而会变成运行时可以分配的动作预算。
这也改变了自然的下一步问题。本文在部署时固定自回归深度,但未来的策略可以在线决定要生成多少 token: 简单动作可以直接用短前缀执行,接触更复杂、精度要求更高的步骤则可以先请求更多 token 再行动。 因此,自适应 token 预算是有序、前缀可解码动作表示直接打开的方向。
后续的 VLA 时代的 Tokens 页面会继续回答其中几个问题: block-wise 自回归生成、VLA cotraining 中的有序 token 监督,以及由连续 expert 执行最终动作的混合控制。
简单运动可以从短前缀执行,接触丰富的步骤可以请求更多 token。
只有在不确定性仍高或精度很重要时,策略才生成额外 token。
即使最终由连续 expert 执行动作,有序 token 仍可提供带动作结构的监督信号。
离散动作推理和 diffusion 或 flow 解码器不必相互竞争。
附录
@misc{liu2026oatorderedactiontokenization,
title={OAT: Ordered Action Tokenization},
author={Chaoqi Liu and Xiaoshen Han and Jiawei Gao and Yue Zhao and Haonan Chen and Yilun Du},
year={2026},
eprint={2602.04215},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2602.04215},
}