Praxis A Controlled Laboratory for Vision-Language-Action Policy Research
Praxis turns VLA studies into policy cells: choose the objective, action representation, backbone, and evaluator, then leave behind an auditable record of what changed.
1Harvard University 2Stanford University
Technical report, June 10, 2026.
Vision-language-action (VLA) policy research now spans pretrained multimodal backbones, discrete action tokenizers, continuous control objectives, and broad simulated benchmarks. Many comparisons, however, remain benchmark-centric: objective, backbone, tokenizer, decoding rule, normalization state, serving path, and benchmark adapter can change together before a rollout score is reported. Such scores are useful for tracking capability, but weak evidence for what caused a difference. We present Praxis, a research substrate for controlled VLA ablation. praxis-vla represents each policy as a matrix cell over objective, action representation, and vision-language model (VLM) backbone, so a study can name the coordinate it changes. praxis-eval moves benchmark semantics, execution mode, dependency isolation, and evaluation records outside policy families. This artifact paper reports no new architecture or leaderboard result; it defines notation, contracts, and executable boundaries for attributing differences in VLA experiments.
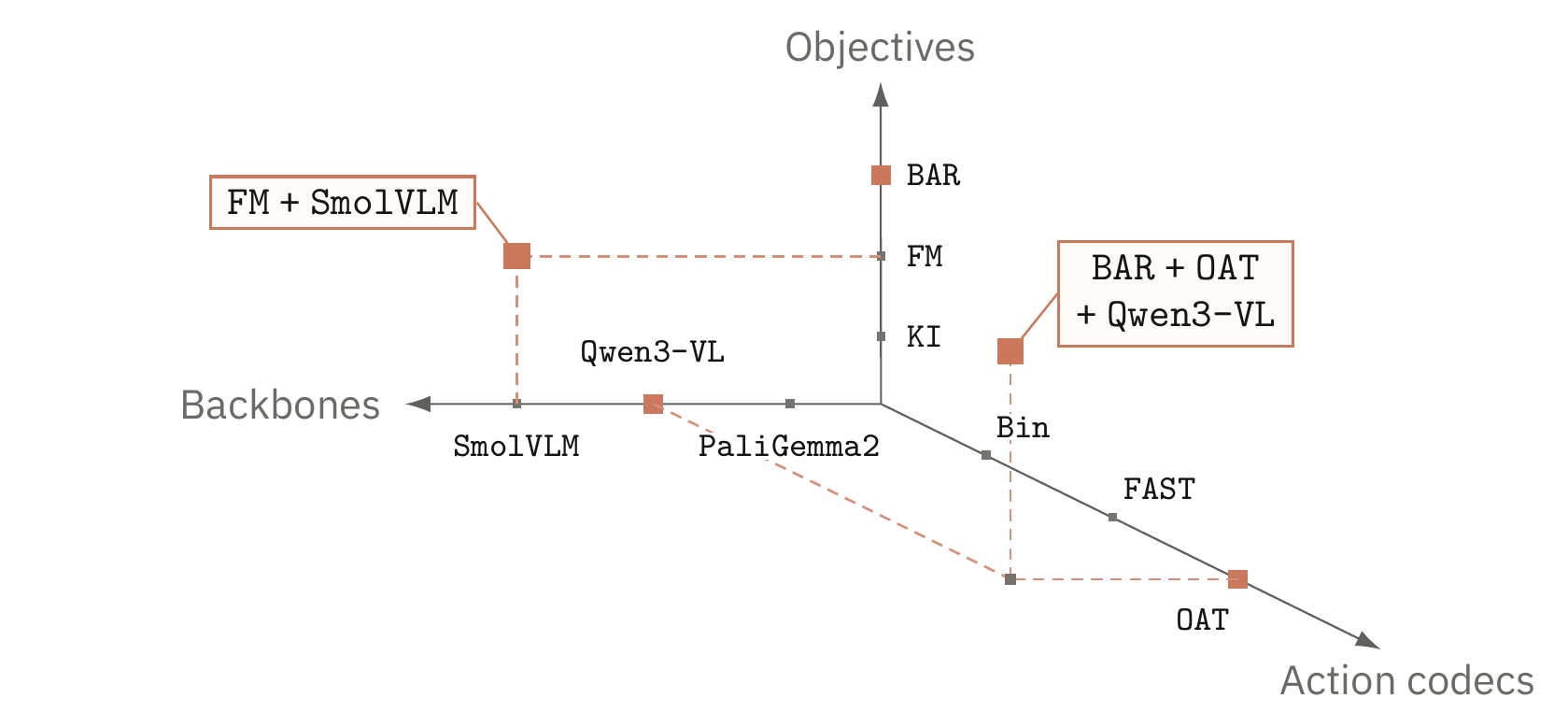
VLA work needs a lab, not another private stack.
A rollout score often bundles the objective, tokenizer, backbone, simulator adapter, normalization state, and serving path into one number. Praxis makes those choices visible before training or evaluation starts.
- The problem: many VLA comparisons replace too much at once, so the measured difference is hard to attribute.
- The method: praxis-vla defines policy cells, while praxis-eval fixes the reset/act boundary that benchmark drivers use.
- The point: a new study can add one objective, codec, backbone, or benchmark without forking the whole lab.
Benchmarks track capability. Praxis tracks the comparison.
VLA systems are now full pipelines. If one paper swaps action tokens, VLM family, processor logic, action normalization, and rollout glue together, it may compare two pipelines rather than one research idea.
Praxis changes the unit of discussion from a named system to a policy cell. The cell states the objective, action representation, VLM backbone, and evaluator interface that are in play.
- Policy cell
- A declared combination of objective, action representation, backbone, and evaluator binding.
- Study axis
- The part of the cell a study intends to move, such as OAT versus bOAT or BAR versus KI.
- Evaluation boundary
- The narrow reset/act protocol that keeps simulator semantics benchmark-owned.
- Artifact record
- The metrics, configs, action specs, logs, and runtime metadata needed to inspect the result.
Praxis is praxis-vla plus praxis-eval.
The brand is intentionally bigger than a single repository. praxis-vla owns the policy side of the matrix. praxis-eval owns the benchmark-facing protocol. Together they let a cell be built, run, and inspected.
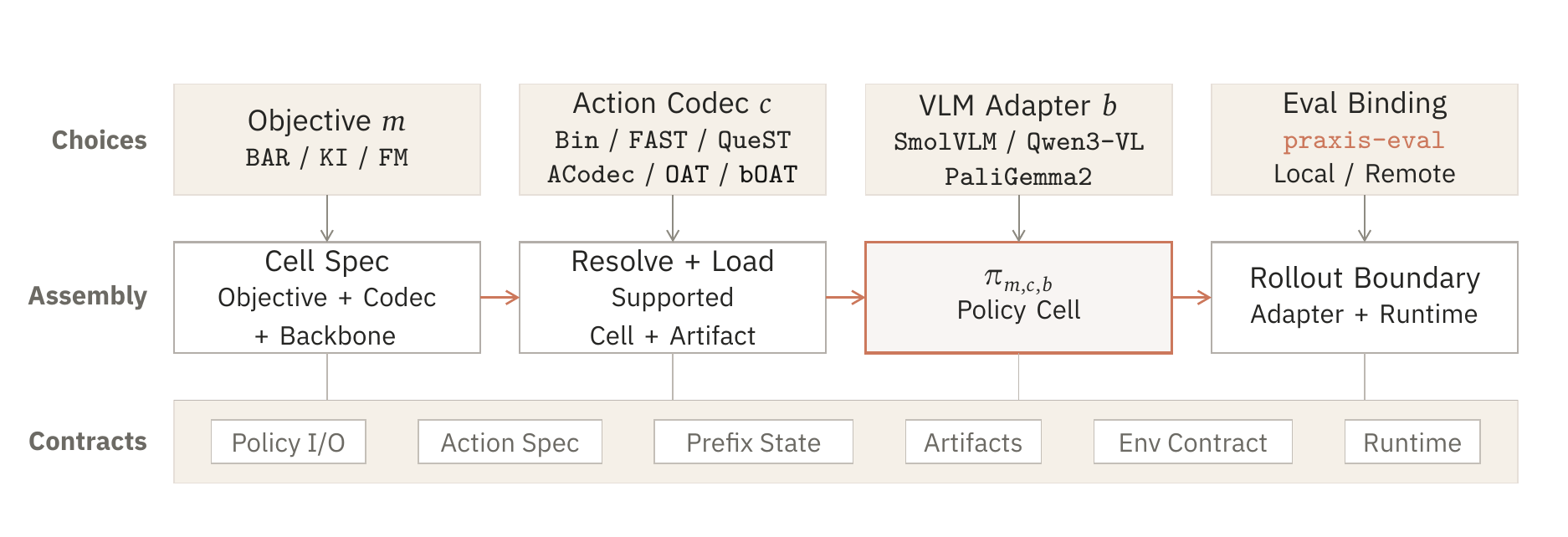
Registers objectives, action representations, VLM adapters, policy I/O, and saved artifacts.
Runs local or remote policies through benchmark drivers with a shared reset/act interface.
Keep the surrounding protocol visible so the result reads as a study, not just a score.
A VLA policy becomes a cell before it becomes a claim.
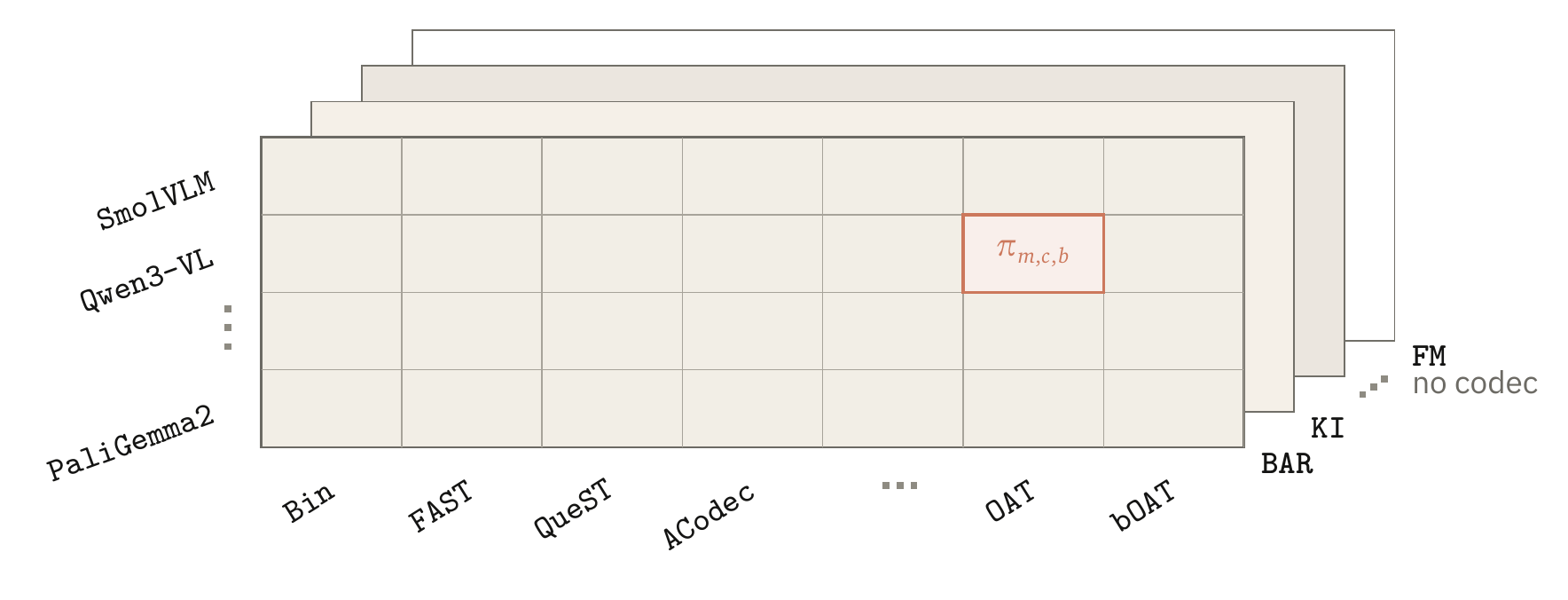
Tokenized policies occupy objective, action-codec, and backbone axes. Tokenless flow-matching policies occupy the objective-backbone plane. The current release is concrete, and the axes are open-ended by design.
BAR predicts action-token blocks, KI supervises VLM context with tokens, and FM predicts continuous action chunks.
Bin, FAST, QueST, ACodec, OAT, and bOAT expose different rate, distortion, and modelability tradeoffs.
SmolVLM, Qwen3-VL, and PaliGemma2 are treated as swappable policy inputs with adapter-owned preprocessing.
Each objective isolates a different control hypothesis.
The policy-cell notation is bookkeeping with teeth. It states what a comparison intends to vary before training, loading, serving, or rollout begins.

- BAR
- Generate action tokens in scheduled blocks, then detokenize them into executable control.
- KI
- Use action tokens as VLM supervision while a continuous expert owns final action generation.
- FM
- Remove the discrete-token axis and predict continuous action chunks directly.
Evaluation is a protocol, not hidden glue.
A policy is meaningful only relative to the observations it receives, the action convention it must satisfy, the tasks selected for rollout, and the simulator runtime that executes those actions. praxis-eval keeps those responsibilities separated.
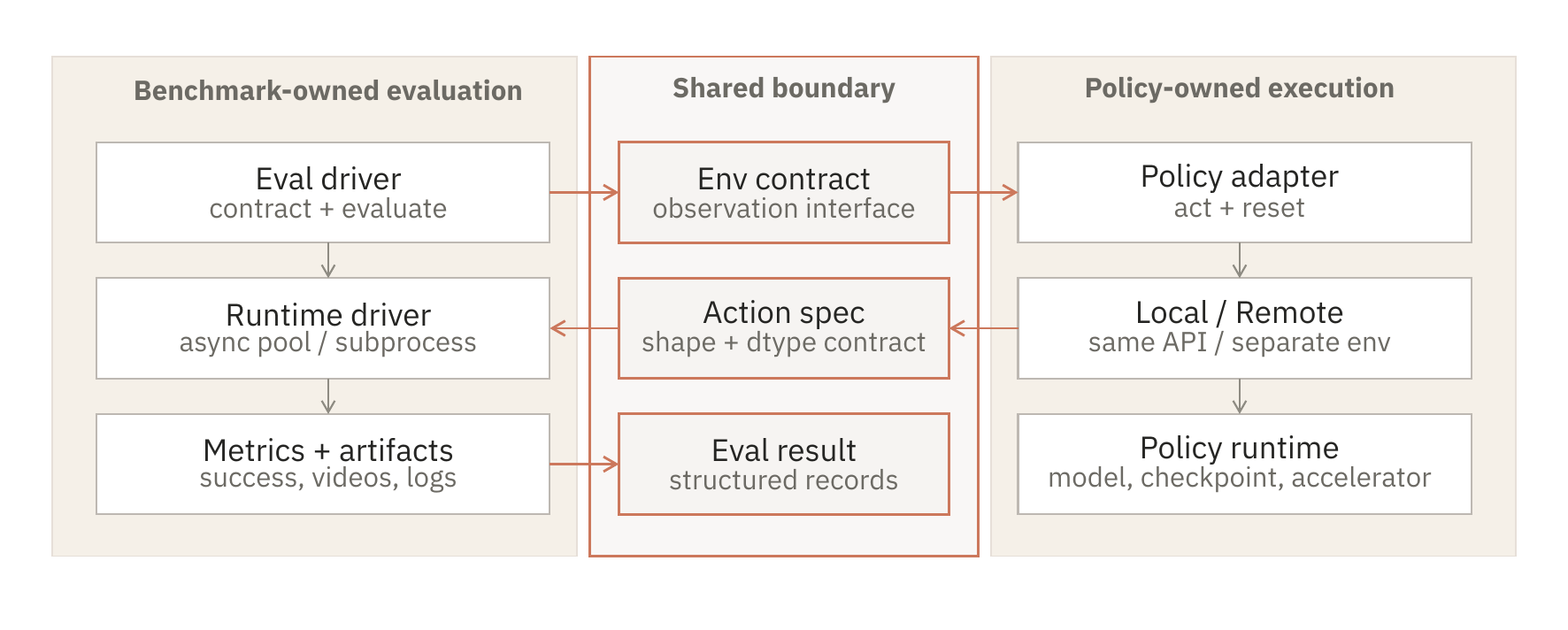
- Benchmark-owned semantics. Task selection, simulator stepping, metrics, and records stay inside the driver.
- Policy-owned execution. The policy exposes reset and act behavior without taking over the evaluator.
- Structured records. Each rollout can carry metrics, artifacts, metadata, and runtime details for later inspection.
New research should extend an axis, not fork the lab.
Praxis is not a closed catalog. It is a structure for adding new objectives, action representations, backbones, and benchmarks while preserving shared interfaces where possible.
- Add an objective. Declare the supervision signal, inference procedure, rollout-state needs, and compatible action representations.
- Add an action representation. Declare token space, decode semantics, prefix behavior, schedules, and validity assumptions.
- Add a VLM backbone. Localize processor, prompt format, image handling, prefix state, hidden geometry, and cache behavior.
- Add a benchmark. Keep simulator semantics in a driver and expose policy-facing observations, actions, metrics, and records.
Appendix
Readers interested in using Praxis should start with the public docs for praxis-vla and praxis-eval.
@misc{liu2026praxis,
title={Praxis: A Controlled Laboratory for Vision-Language-Action Policy Research},
author={Liu, Chaoqi},
year={2026},
url={https://ordered-action-tokenization.github.io/praxis/}
}